


Beszélt és írott magyar szöveg feldolgozását lehetővé tevő modellt építettek a Pécsi Tudományegyetemen

Mindenki szívesebben használja az anyanyelvét chat és más automatizált alkalmazásokban. Mivel azonban a magyar nyelvet mindössze 15 millióan beszélik világszerte, a cégek számára gyakran nem éri meg kifejleszteni a feldolgozásához szükséges szoftvereket. A Pécsi Tudományegyetem (PTE) Alkalmazott Adattudományi és Mesterséges Intelligencia-csapata felismerve ezt a problémát a Microsoft Azure mesterséges intelligencia és az ONNX Runtime megoldások alkalmazásával megépítette és betanította saját BERT-large modelljét magyar nyelven, méghozzá kevesebb, mint 200 munkaóra és 1000 euró befektetésével.
A Pécsi Tudományegyetem számára kulcsfontosságú terület lett a mesterséges intelligencia és a felhőalapú oktatás, amióta partnerkapcsolatot építettek ki a Microsoft Mesterséges Intelligencia Tudásközpont program keretein belül 2019-ben.
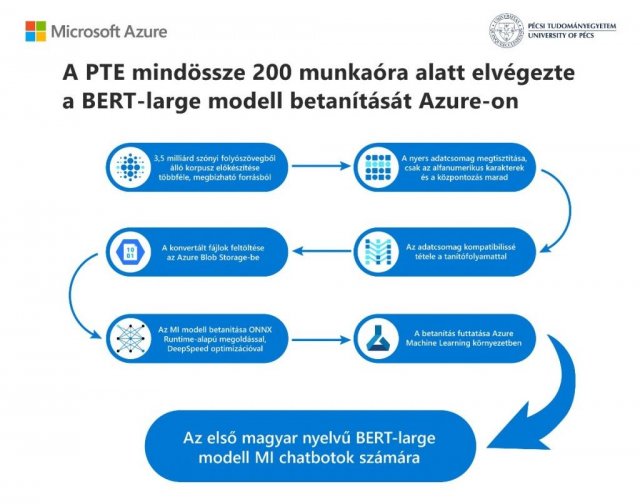
A nagy mennyiségű magyar nyelvű adat kezelését megkönnyítendő a PTE természetes nyelvfeldolgozási (NLP) módszerek kutatásába fogott. A megoldást egy magyar nyelvű BERT-large modell (HILBERT) létrehozása jelentette, ami egy nyílt forráskódú gépi tanulás keretrendszer. A modell célja, hogy segítse a számítógépet a többféleképpen értelmezhető szövegrészek megértésében oly módon, hogy a szövegkörnyezetből kontextust épít.
A csapat az Azure mesterséges intelligencia használata mellett döntött a saját, magyar nyelvű BERT-large modelljük megalkotásához.
“A Microsoft piacvezető a nyelvi modellek betanításának területén. Természetes, hogy a legjobb technológiát akartuk használni” – mondta el Hajdu Róbert, az Alkalmazott Adattudományi és Mesterséges Intelligencia Központ volt tervezőmérnöke. Ráadásul a csapat már ismerte az Azure szolgáltatást, ez is egy érv volt mellette.
Ahelyett, hogy gyenge minőségű adatokat gyűjtöttek volna az internetről, a Nyelvtudományi Kutatóközpont szakemberei segítségével készítették elő az alapokat. Az Azure pedig mindent megkönnyített és felgyorsított.
A modell betanítására szintén gyors és költséghatékony megoldást kerestek: a Microsoft ONNX Runtime DeepSpeed könyvtárát választották a feladathoz, amit az Azure Machine Learning (AML) platformon futtattak. E platform segítségével hatékonyan tudtak haladni a mesterséges intelligencia modellek építésével, munkába állításával, menedzsmentjével és nyomonkövetésével. Így a csapat közben olyan más feladatokra koncentrálhatott, mint például az adatkezelés.
A modell működéséhez egyébként legalább 3,5 milliárd szót tartalmazó folyószöveg szükséges, ezt az adatbázist a Nyelvtudományi Kutatóközpont, a projekt másik résztvevője többek között a Magyar Nemzeti Szótárból, online médiatárakból és az opensubtitles.org ingyenesen hozzáférhető filmfelirat-adatbázis magyar nyelvű anyagai közül gyűjtötte a csapat.
Habár a pandémia alatt mindannyian otthonról dolgoztak, a BERT-large betanítási folyamata az Azure-on semmilyen problémát nem okozott.
“200 munkaóra alatt végeztünk. Ez a világon az eddigi legolcsóbb BERT-large. Kevesebb, mint 1000 euróba került” – mesélte büszkén Dr. Feldmann Ádám, a PTE Adattudományi és AI csoport vezetője. “Az ONNX Runtime nélkül a HILBERT-large modellünk betanítása 1500 órát, vagyis megközelítőleg két hónapot vett volna igénybe” – hívja fel a figyelmet.
A Pécsi Tudományegyetem BERT-large modellje jelentős lehetőségeket rejt magában az írott és beszélt szöveg feldolgozása, az intelligens keresés, az entitásérzékelés, a dokumentációs klasszifikáció terén. A HILBERT közreműködhet újabb, jobb teljesítményű chatbotok létrehozásában is.
Mindez pedig segítheti a magyarokat a könnyen érthető, releváns információkhoz való hozzáférésben, különösen a Covid-19 körüli félretájékoztatás elleni küzdelemben. Számos egészségügyi és kormányzati szereplő is érdeklődött már a HILBERT-large modell iránt.
A projekt teljes ismertetője ezen a linken olvasható.
Kapcsolódó cikkek
- Német művész érkezik a SZTAKI-ba, hogy robotot építő robotot építsen
- A Xiaomi öt új okoseszközt mutatott be
- A Dell Technologies Omnia szoftverével felgyorsíthatók az innovációs folyamatok
- Az adathalászat által legjobban sújtott brand továbbra is a Microsoft
- A hibrid munkakörnyezet több érzékenységet és rugalmasságot kíván meg a vezetőktől
- A jövő AI alapú ellátási láncai most alakulnak
- A Fujitsu mesterséges intelligenciája vigyázza a Nürburgring versenypálya biztonságát
- OMSZ–Dyntell: látják a jövőt
- Digitális készségekkel vértezte fel magát a hazai civil szektor
- MI TUDÁSKÖZPONTOK: Robotszimuláció támogatja az önvezető járművek fejlesztését
Megoldás ROVAT TOVÁBBI HÍREI
Siemens Xcelerator: az Eplan és a Siemens zökkenőmentes adatátvitelt tesz lehetővé a gépgyártásban
A Siemens és az Eplan hatékonyabbá teszi a tervezési és gyártási folyamatokat a gépeket és gyártósorokat építő ügyfeleik számára.
A Z-generáció tudja milyen munkahelyet szeretne
Az önérvényesítés, a munkahelyi környezet, az anyagiak, a társas kapcsolatok, valamint a kreativitás, illetve a szellemi ösztönzők azok a legfőbb munkaértékek, amelyek a STEM pályára lépő Z-generációs fiatalok számára meghatározóak a leendő munkahelyük kiválasztásában és az ottani megmaradásukban – derül ki a Becsei Lilla pályaorientációs szakember friss, országos, reprezentatív kutatásából, amit az Együtt a Jövő Mérnökei Szövetséggel együttműködésben készített el a 12. osztályos magyar tanulók körében.