


2500 oldalnyi Google dokumentum, köztük rengeteg rangsorolási szignál szivárgott ki!

Mintegy 2500 oldalnyi Google dokumentum került nyilvánosságra, melyekben rengeteg rangsorolásra vonatkozó konkrét információi is megtalálható. Sose volt hasonló adatszivárgás a Google-nál. Szuhi Attila, az ITE.hu alapítója és főszerkesztője mutatja a részleteket.
Milyen dokumentumok szivárogtak ki?
Körülbelül 2500 oldalnyi Google Search API dokumentáció szivárgott ki, amely 14,014 attribútumot (API jellemzőket) tartalmaz. Ezek az API dokumentumok a Google belső „Content API Warehouse” rendszeréből származnak. A dokumentáció tartalmaz részletes adatokat arról, hogy Google milyen adatokat gyűjt és hogyan működik a keresési algoritmusai.
Milyen módon kerültek ki?
A dokumentumok március 27. és május 7. között kerültek fel a GitHub-ra, valószínűleg véletlenül, és onnan terjedtek tovább. Az API dokumentációt egy külső automatizált dokumentációs szolgáltatás is indexelte, így jelenleg is elérhetőek.
Egy kis háttérsztori
Az adatokat szélesebb körben Rand Fishkin tette közzé aki egy névtelen forrás révén szerzett tudomást a dokumentumokról. Május 5-én kapott egy e-mailt egy személytől, aki hozzáférést biztosított neki a Google Search divízió belső API dokumentációjának hatalmas mennyiségű adatához. Fishkin hitelesnek találta az információkat, mivel azokat valódiságát Google-alkalmazottak is megerősítették. Fishkin közvetlenül felvette a kapcsolatot a névtelen forrással, és egy videóhívás során részletesen átbeszélték a dokumentumokat. Fishkin a szivárgás hitelességét további ex-Googler-ek segítségével is megerősítette, majd segítséget kért Mike Kingtől, a világ egyik vezető technikai SEO szakértőjétől, hogy segítsen elemezni a dokumentumokat.
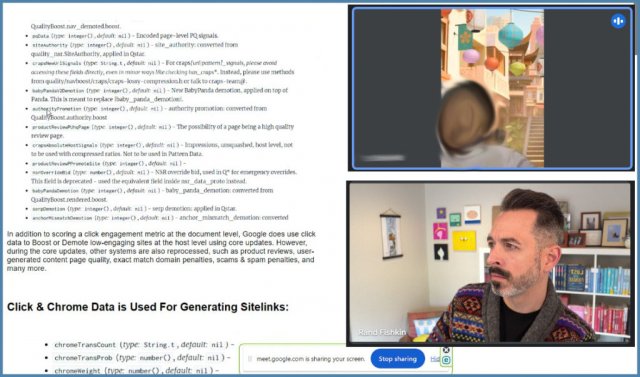
Mennyire hitelesek az információk?
A dokumentumok hitelességét több volt Google-alkalmazott is megerősítette. Bár nem mindegyikük akart vagy tudott nyilatkozni, azok, akik átnézték a dokumentumokat, úgy találták, hogy azok valódiak és belső Google szabványoknak megfelelően készültek. A dokumentumban 2023. augusztusi dátumukra való hivatkozás található, tehát friss információkról van szó.
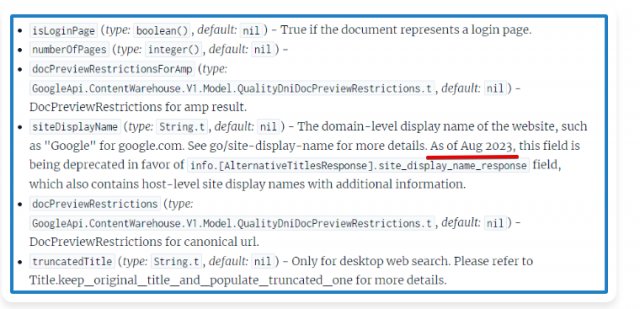
Mi az a Google API Content Warehouse?
A Google API Content Warehouse egy belső rendszer, amely API attribútumokat és modulokat tartalmaz. Ezek az attribútumok és modulok segítenek a Google keresőcsapatának megérteni, milyen adatokat gyűjtenek és hogyan használják fel ezeket az adatokat a keresési algoritmusok fejlesztésére és finomítására.
Nem könnyen feldolgozható
Az anyag nem könnyen feldolgozható, sok helyen az egyes attributumokhoz nincs magyarázat, vagy az nehezen érthető, és ezek visszafejtése időt igényel. Íme, egy mint a dokumentációból:

Ezekben rangsorolási faktorok találhatóak, amiket a Google a mai napig használ?
Valószínűleg igen, minden jel erre mutat, hogy ezek valós adatok, és ezeket a Google valóban használja. A dátumok alapján vélhetően ezek zöme a mai napig használatban van. Az adatok hitelességét megerősíti az, hogy az jól egyezik a Google szabadalmakban és a Google trösztellenes anyagaiban talált információkkal.
A SEO Klubban néhány hónapja készítettem egy kb 50 oldalas anyagot, ami a trösztellenes anyagokból kiszivárgott rangsorolási információkkal foglalkozik, és az ottani anyagokkal jól egybevág a mostani információhalmaz.
Rangsorolási súlyok azonban nincsenek az anyagban.
Mi a jelentősége a mostani szivárgásnak?
A mostani szivárgáshoz hasonló sem történt még soha a Google-nál, a trösztellenes anyagokkal együtt a legfőbb következtetések az alábbiak:
• a rangsorolás alapvetően másképp működik, mint ahogy gondoltuk, kulcsfontosságú szerepe van a felhasználói adatokra alapozott rangsorolási faktoroknak (lásd a trösztellenes anyag tanulságait)
• a Google szóvivői nem hogy csúsztatnak, de tudatosan félrevezetnek, és szándékosan hazudnak a rangsorolási szignálokról
• a két anyag segítségével a keresőoptimalizálás alapvetően átalakulhat: sokkal pontosabban tudjuk majd mi számít bele a rangsorolásba, és alapvetően új szemlélet alakulhat ki, ami eredményesebbé teheti a keresőoptimalimzálást
Rangsorolási szempontok a dokumentum alapján
Nagyjából 4 órával ezelőtt találkoztam a dokumentummal, így még nagyon az elején járok az anyag feldolgozásának, de íme néhány érdekesség, messze a teljesség igénye nélkül:
A Google masszívan használja a felhasználói adatokat
A dokumentumban rengeteg attribútum utal arra, hogy a Google a felhasználói átkattintási adatokat használja a rangsorolásban:

A badClicks, goodClicks, last longestClicks és a többi hasonló attribútum egyértelműen utal erre, ráadásul a kattintások jól láthatóan osztályozva is vannak.
Érdemes megemlíteni, hogy a Google szóvivői mind tagadták és cáfolták, hogy ezeket az adatokat használnák a rangsorolásban, pl:
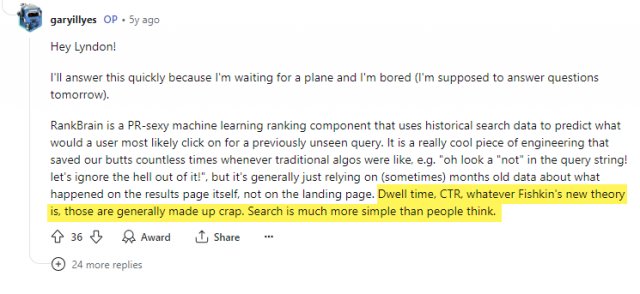
Chrome adatok felhasználás a rangsorolásban
Szintén egyértelműen kiderül, hogy a Chrome-böngésző felhasználói adatai is szerepet kapnak a rangsorolásban:

A Chrome több helyen is felbukkan a dokumentumban és tudni lehet, hogy a Google a böngésző fejlesztésével elsősorban arra koncentrált, hogy megfelelő mennyiségű felhasználói adattal rendelkezzen.
Gondold át mit jelent mindez! Vajon azok a nagy brandek, akiket mindenki ismer, és akinek a neve azonnal feltűnik a találati listán ( ahogy a Mars csokit is felismered a boltban) vajon milyen átkattintási adatokat tudnak elérni egy kisebb webáruházzal szemben?
A márkaismertség fontossága eddig is ismert volt, de most még egyértelműbb ennek a jelentősége.
Pingvin és link statisztikák
Ahogy említettem 2500 dokumentumról (modulról) van szó, ezek közül egyben említik a Pingvin algoritmust is. De nem csak azt, hanem azt is, hogy milyen statisztikákat gyűjt a Google a horgonyokról a rangsoroláshoz.
Pusztán ez az egyetlen modul nagyjából 60 különbözö szempontot sorol fel!
Például, ha egy oldal túl sok linket kap, akkor nem kap Pingvin pontszámot ( ami a rossz linkeket büntetné):

Hadd mondjak el ehhez egy történetet, van egy ügyfelem, aki évek óta rendel linkeket minden esetben ugyan azzal a horgonyszöveggel. Elmagyaráztam neki ez miért rossz ötlet, milyen veszélyei vannak. Ő elmondta, hogy ismeri és tud ezekről a kockázatokról, de bevállalja. Ma már több száz domainről kap hivatkozást ugyan azzal az egyetlen egy horgonyszöveggel. Évek óta első a találati listán. Nem azt mondom, hogy ez feltétlenül követendő, csak azt, hogy a 14 ezer attribútumból itt van egy, ami magyarázatot ad erre a jelenségre.
De kiderül a dokumentációból az is, hogy a régi, megbízható linkek védettséget adnak a Pingvin algoritmus ellen:

De, nézzük például a topPROnsiteAnchorCount attribútumot! Ez a mező egy olyan számot jelöl, amely a legjobb minőségű, az oldalon belüli horgonyokat (linkeket) számlálja. A horgonyok minőségét a PageRank segítségével mérik. Az Anchor Quality Bucket a kifejezés a horgonyok minőségi kategorizálására utal. A horgonyok különböző „vödrökbe” (bucketekbe) vannak sorolva a minőségük alapján.
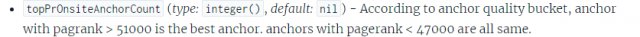
Hallottál már a SnippetBrain-ről?
Vélhetően ez is a Google egy mélytanulásos algorimusa, aminek a feladata találati listán megjelenő kivonatok minőségének értékelése.

A dokumentumból kiderül, hogy létezik egy ilyen modell, ami értékeli a kivonatokat és figyelmbe veszi például, hogy a felhasználó keresése kiváltja-e a félkövér kiemelést a találati listán (ami ezek szerint rangsorolási tényezőnek számít).
De a további dokmentumokból megtudhatjuk, hogy milyen egyéb szempontok alapján értékelődik ki a kivonat, amihez például a dokumentum adatait is felhasználják.
Az is világos, hogy a meta leírásnak igenis fontos szerepe lehet a rangsorolásban, épp a felhasználói interkciók miatt.
A kis oldalakat külön kezeli a Google
Azt is lehet tudni, hogy a Google-nek külön rangsorolási faktora van a kis, személyes weboldalakra vonatkozóan. A smallPersonalSite nevű attribútum egyértelműen ezeket a weboldalakat azonosítja és pontot rendel hozzájuk. Vélhetően ez egy pozitív, támogató rangsorolási szignál.
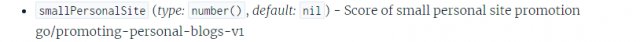
Vannak kiemelt oldalak
És azt is lehet tudni, hogy vannak kiemelt oldalak, amelyek külön előnyt élveznek, például a COVID járvány alatt bizonyos oldalak, de vannak kiemelt oldalak választások idején, sőt van egy un. GoodTravel Site modul is, ami aggasztó lehet az utazással foglalkozó weboldalak számára:

Például látható, hogy egy hotel hivatalos oldala szintén rangsorolási előnyt élvezhet.
Mi derül ki még?
Fent hoztam pár példát, de ez csak a teljes anyagmennyiségnek egy apró töredéke, ami eddig megkapta a figyelmemet, de rengeteg információ van: 2500 oldal, 14 ezernél több atribútum, azaz rangsorolási szempont.
A tervem az, hogy ezeket megpróbálom mind lefordítani, majd közérthető formába önteni. Ez jelenleg óriási munkának tűnik. Nem csak arról van szó, hogy a dokumentum nagy (2500 modul) hanem sok esetben a dokumentációhoz nincs magyarázat és úgy kell visszafejteni az egyes attributumok elnevezése alapján azok lehetséges feladatát. Pl. ilyen adatok mellett nehéz visszafejteni miről is lehet szó:

A terveim szerint – ha sikerül megcsinálni – akkor ebből lesz egy anyag, ami a SEO Klub keretében lesz elérhető (tekintve a befektetett munka mennyiségét), de kisebb kivonatokat majd lehet nyilvánosan is publikálok.
Reálisan első ránézésre 1-3 ezerre teszem azon rangsorolási tényezők ( attributumok) számát ami visszafejthető az anyagból. Ez így is kb százszorosa a jelenleg biztosan tudott rangsorolási faktorok számának.
Ha mindezzel megleszünk a következő feladat pedig, hogy ezeket az ismertté vált szempontokat hogyan alakítjuk át napi SEO munkává.
A teljes dokumentum innen érhető el: https://hexdocs.pm/google_api_content_warehouse/0.3.0/api-reference.html
Szerző: Szuhi Attila
Forrás: ite.hu/2500-oldalnyi-google-dokumentum-koztuk-rengeteg-rangsorolasi-szignal-szivargott-ki/
Kapcsolódó cikkek
- Drámai változás a Google Hírekben: Nem vehető fel több kiadvány
- Újgenerációs, sajátmárkás készülékek a Telekomnál
- Ismét találkozhatunk a Google Utcakép autóival
- Váratlant lépett a Google: erre nagyon figyelj szolgáltatóként!
- Google atombomba: kombinált Core, Spam és HCU algoritmus frissítés egyszerre
- Elérhető a Google Gemini ultra változata a Gemini Advanced
- A Google, a HP és az ASM is csatlakoztak a Schneider Electric kezdeményezéséhez
- Újabb UNESCO látványosságokkal bővült a Google Arts & Culture magyarországi listája
- Az év keresésekben: Google keresési trendek 2023
- A Google Maps segít, hogy igazán gördülékeny legyen az ünnepi készülődés